7/31/2014
HP SIM, WBEM enabling Hyper-V guests
Step by Step
1. rdp to guest
2. copy WMIMapper2_6_0.msi and install, Typical
c:\WMIMapper2_6_0.msi INDICATIONSSUPPORT=yes
3. configure SIM with new [options - protocol settings - WMI Mapper Proxy]
4. configure SIM [WMI Mapper Proxy - New - Add WMI Mapper Proxy][IP address of guest]
5. configured Windows Firewall to allow access to port 5989 from SIM server IP address
6. configure [DCOM Services - Computers - MyComputer - rtClick Properties]
7. configure [DCOM Services - Computers - Windows Management Services - rtClick Properties]
8. configure [rtClick Computer - Manage - Configuration - WMI Control - Security - Root - Security]
9. [ advanced - Add - User - Object - Check all permissions - This namespace and subnamespaces]
10. [ck] Apply thesze permissions to objects and/or containers within this container only ]
11. configure [Services - WMI]
12. configure SIM [options - discovery - run]
7/28/2014
PXE, iPXE macro problems
So porting of the code over to the iPXE code base was going really fast until I found the src/includes/ipxe/tables.h "Macro" library for defining __tables was redefined, and no longer accepted three parameters.
I'm still trying to grasp the significance of this while studying up on all the different ways a Macro can be used.
According to this (lots):
The C Preprocessor
Macros
A macro is a fragment of code which has been given a name. Whenever the name is used, it is replaced by the contents of the macro. There are two kinds of macros. They differ mostly in what they look like when they are used. Object-like macros resemble data objects when used, function-like macros resemble function calls.
So the Linker issue was a bad path to go down, it started in gPXE and the reason the table.h is different is probably not for that reason.
Both gPXE and iPXE however have some Doxygen Commenting in the code which can be used to generate documentation from the embedded doxygen comments.
# cd gPXE
# cd src
# make doc
# cd src/bin/doc/html
# firefox index.html
centos 5.9 only has doxygen 1.4.7-2 so it will not compile the 1.5.7.1 version of the latest iPXE doxygen.cfg
# wget ftp://ftp.stack.nl/pub/users/dimitri/doxygen-1.5.7.1.src.tar.gz
# tar -zxvf
# ./configure
# make install
# cd iPXE
# cd src
# make doc
# cd src/bin/doc/html
# firefox index.html
Etherboot documentation on how to write a driver (ancient)
Etherboot developers manual - one of the best
Another 2003 version of Etherboot Developers Manual
iPXE page mostly criteria
Doxygen file for iPXE project
gPXE driver API documentation
Where do I start with developing a new driver?
Michael Decker's gPXE driver API documentation shows the interface that a driver must implement.
Study the code ingpxe/src/drivers/net. Thertl8139andr8169drivers are good examples. Note that some drivers are not written for the gPXE API but use a wrapper for the legacy Etherboot API instead. New drivers should use the gPXE API.
Linux Device Drivers is a good reference for understanding Linux drivers and learning general driver development concepts.
http://etherboot.org/wiki/appnotesSlide show from a Course of Device Drivers
Related Links from Etherboot
http://netboot.sourceforge.net/english/index.shtml
MiT etherboot-4.4.5 info
netboot (packet driver days) -> etherboot (ISA probing days) -> gpxe -> ipxe
So end of the night.
As far as I can tell the old Etherboot criteria for a minimum of four or five functions stands, at least as legacy.c wrappered -- it looks like as time went on they kept adding requirements
The src/core/main.c file calls some init.c/h functions and starts up performs housekeeping and runs a "probe" function for each "linked in" driver to see if it detects its hardware. If it does it returns a structure with the mac address and other info and leaves the device in "ready to transmit" mode.
This is probably the opportunity to setup and start the USB bus, like the PCI bus, ect.. the latest iPXE seems to have a USB bus for storage devices.. I wonder if it will conflict, or be preferred since it must share the bus with storage and ethernet devices.
If they should share then it would make sense to adopt that USB communications provided for the EDD or storage bus and adapt the NIC-ish functions to that method. Otherwise two USB drivers for the same bus would not be good. This tells meThe main loop then performs its other tasks and calls dhcp function which uses some tcp and network functions to "use" the netdevice to perform the communications.ipxe/src/drivers/net/rtl8139andr8169drivers might be good prototypes to study.. unless some legacy wrapping is going on to the new ipxe standard api.. whatever that might be.
I'm not entirely convinced the tables.h definition needs to be used by the driver code, it appears to be utility code to simplify things. Might be just as well to create second macro definition and use that, or embed what its trying to provide directly in the driver code.
Its really tough luck the two functions that won't compile are the "probe" functions for the detected hardware. They fillout or "sketch out" how to use the netdevice for the main routine.
Lots of confusion on my part, but in a vacuum it probably more efficient than doing nothing.
7/26/2014
PXE, diskless booting with a USB nic and Flash over HTTP
Now that the hard part is over:
One of the things Git and version control systems do not capture are the details about the actual hardware used to develop the code, or how testing was performed.

PXE, Sys etherboot gPXE and iPXE
PXE, gPXE now pulling dhcp and image
First I used a Combo Adapter (Although its called MacBook, it is an ASIX AX88772A device that works with everything from Windows 98/ME through Windows 7, and OSX 10.3 through 10.7 and Linux 2.4 or better) so its about as flexible a device as your likely to find.
Its available from a lot of places, but specifically here is a place that seems to provide a lot of details
USB to Ethernet Adaptor 2 Ports USB Hub Reader

On the other side are a number of memory card ports, including SD/M2/TF(microSD).

Carrying this out to its extreme conclusion, my hope was that most Laptops and Notebooks without an Ethernet port would have at a minimum a USB port, which could then be used with a Multi-function device like this to attach additional Flash memory devices or memory cards.
Now that gPXE has been proven to activate and PXE over [ http ] from this device (which opens up iSCSI, AOE, https.. and of course tftp). The next logical step would be to see if if could be written to a memory card, then inserted and booted from.
The boot feature would only require the Laptop or Notebook at a minimum support the USB hub type and to recognize a memory card or flash drive as a bootable device which many in Legacy mode will do.
The diverse form factor of the ports means boot media could be collected in one form and either used directly in a Laptop or Notebook port or in the Combo device itself.
I would also like to complete porting the gPXE driver set for this to iPXE.. and "then" explore WiFi booting over a similar USB nic device from ASUS
This is a complete linux type computer with a dhcp server, router and firewall in a tiny form factor, and its is bus powered.

ASUS WL-330NUL
In fact since it contains all the server and WiFi componets to support ad-hoc networking, it could be attached to the end of the Combo adapter above and provide a Wireless bridging function to boot off a WiFi enabled infrastructure.One end is an Ethernet plug, the other end is a USB pigtail type connector.. so it could be attached Ethernet-to-Ethernet or Daisy chained off the Combo adapter USB hub.. but I tend to think E-to-E would be a faster thing to do.
If all of three components could be packaged into a single chip form factor.. the result would be something as useful as USB universal communications adapter.. which could be used either to retro-fit older computers with modern facilities for remote booting.. or uploading and backup.. diagnostics, provisioning.. forensics.. or on the spot networking of a node cluster in short order.
One of the things Data Centers today still have a problem with is node bridging and the inherent lack of thought that goes into network pathing.. if its merely a chip on every motherboard like an ipmi, bmc or ilo.. that becomes a lot less of a problem.
For consumers.. devices without brains (DWB) or "DWeeBs" could become very attractive as their prices fall and "form factor" takes an even more forward position in their value and design.
7/25/2014
PXE, gPXE now pulling dhcp and image
Somewhat unexpectantly.
It appears the driver works with only a minor change.
Originally the driver detected the USB to NIC adapter that I had, but it timed out.

So once I setup a test environment.
I looked over the code and noticed something peculiar.
static struct usb_device_id asix_88178_ids[] = {
USB_ROM (0x0b95, 0x772a, "asix", "ASIX AX88x72A"),
USB_ROM (0x1737, 0x0039, "asix", "Linksys USB1000"),
USB_ROM (0x04bb, 0x0939, "asix", "IO-DATA ETG-US2"),
USB_ROM (0x050d, 0x5055, "asix", "Belkin F5D5055"),
};
static struct usb_device_id asix_88772_ids[] = {These seem to designate the "class" of binding function needed by the device:
USB_ROM (0x2001, 0x3c05, "asix", "DLink DUB-E100"),
};
struct usb_driver asix_88178_usb_driver __usb_driver = {
.ids = asix_88178_ids,
.id_count = (sizeof(asix_88178_ids) / sizeof(asix_88178_ids[0])),
.probe = asix_88178_probe,
};
struct usb_driver asix_88772_usb_driver __usb_driver = {
.ids = asix_88772_ids,
.id_count = (sizeof(asix_88772_ids) / sizeof(asix_88772_ids[0])),
.probe = asix_88772_probe,
};
But I knew from reading the driver code for the Linux kernel and from the Asix documentation that these were 10/100 or 10/100/1000 adapters:
=====================================================
ASIX AX88178 USB2.0 Gigabit Ethernet Network Adapter
ASIX AX88772 USB2.0 Fast Ethernet Network Adapter
Driver Compilation & Configuration on the Linux
=====================================================
It appeared the AX88772A adapter I had [ 0x0b95, 0x772a ] was "misclassified"
I reasoned it was being initalized as a 1000 Mbps device, when it is actually a 100 Mbps device.
So I moved the definition to the other category and recompiled.
This time it worked!

It pulled a dhcp address from my local network and appeared in the leases file for my local lan dhcp server.
The only change was this
static struct usb_device_id asix_88178_ids[] = {Hardly worth a changelog edit.
USB_ROM (0x1737, 0x0039, "asix", "Linksys USB1000"),
USB_ROM (0x04bb, 0x0939, "asix", "IO-DATA ETG-US2"),
USB_ROM (0x050d, 0x5055, "asix", "Belkin F5D5055"),
};
static struct usb_device_id asix_88772_ids[] = {
USB_ROM (0x2001, 0x3c05, "asix", "DLink DUB-E100"),
USB_ROM (0x0b95, 0x772a, "asix", "ASIX AX88772A"),
};
Next task is to see if I can pull a PXE bootable image and boot into that kernel image.
Success (sort of..)
CTRL-B to get to a gPXE prompt
[ I am using a tinyweb server that requires file extensions to serve the files, so I renamed bz2bzImage to bz2bzImage.0 below ]
# dhcp net0
# kernel -n bz2bzImage http://192.168.2.125/gtest/bz2bzImage.0 root=100
# initrd http://192.168.2.125/gtest/initrd.bz2
# boot bz2bzImage
I can manually use the USB to NIC adapter to pull over a kernel image and an initrd image, and manually boot them

It boots to a TomRtBt image, after login all looks familar:

So weirdness "aside" we can conclude the usb subsystem and the usb driver in the gPXE image does indeed work.
For some reason gPXE isn't recognizing the net0 device created by the driver as a valid boot device and produces the following when left up to the command line arguments to automatically boot
# qemu -cdrom gpxe.iso -net user -usbdevice host:0b95:772a -bootp http://192.168.2.125/gtest/gtest.gpxe

This "does" explain why gpxe.usb will not load (it has to be "padded" before it will load)
http://support.etherboot.org/index.php?do=details&task_id=23
The error message "Could not load gPXE" is displayed.The fix appears to download the perl code and add it to the util directory for gpxe src, then use it manually if planning to boot the gpxe.usb in a virtual machine, like qemu
Instead of loading gPXE from disk one sector at a time, this code tries to read
an entire track at once. The size of the image is not taken into account here.
This code will read beyond the end of disk if a virtual machine is run from the
gPXE USB image. Boot will only succeed if the image file size is greater or
equal to the gPXE image size rounded up by 32 KB.
Physical machines and disk media are not affected because they will be larger
than the gPXE USB image size and aligned to 32KB (sectors-per-track).
The following workaround will pad the USB image appropriately:
$ util/padimg.pl -s 32768 bin/rtl8139.usb
The file size is now a multiple of 32 KB:
http://git.etherboot.org/?p=gpxe.git;a=commit;h=7741546a406217827c3d4a8d72aaa322b2565c35
$ ls -alF bin/rtl8139.usb | awk '{ print $5 }'
98304
This might explain the 'lack of ' enumeration
...for the USB nic (or detecting that it is indeed bootable).
Summary is the Boot Firmware Table is not being updated by the detection of the USB nic. If a second virtual nic is added and detected by gPXE it will indicate the USB nic designated nic0 is "inaccessible" and attempt to use the second virtual nic.. which would not be a valid test.
Here is the reference that put me on to the idea:
http://serverfault.com/questions/477708/second-nic-not-working-properly-on-diskless-server-2012
Neither gPXE 1.0.0 nor the Jan. 31, 2013 commit of its successor, iPXE, ever write multiple NICs to the iBFT, even where there are multiple NICs they know about. I've verified this by examination of their source code. My hacky solution was to get the iPXE source tree, and modify the program such that it writes a second NIC section to the iBFT, corresponding to the other NIC in my server (the NIC I was not booting from.)Which suggests to me the insertion or detection code should be making a call to a function that updates the device list, but is not.. if that can be found and called.. everything should work as expected.
A wonky way to get it to automatically work
I noticed a message "No filename or root path specified" and tracked that down to
src/usr/autoboot.c
Which indicated it was trying to source the boot file name from the dhcp call for net0.
(aka the USB nic)
So I put the path
http://192.168.2.125/gtest/gtest.gpxe into the tftpd32 [ Boot File ] field dhcp tab

And that worked
And now the wonky part..
# qemu -hda bin/gpxe.usb -bootp http://192.168.2.125/gtest/gtest.gpxe -usbdevice host:0b95:772a -net nic -net userThe qemu arguments for booting from a nic and providing a bootp file path are still required or it doesn't work.. I'm not sure why.. but that tells me for some reason the arguments from qemu are not being sourced when attempting to boot from net0 but they are being sourced when booting from net1.
That kind of leads me to believe the problem is with qemu and the way it handles arguments for nic devices it supports. Since the usb nic is being "passed-through" using usbdevice instead of emulated it could be the bootp option isn't interacting with the enumeration mechanism properly.
Bottom line: I think this problem lies in [qemu] and the USB pass through, not with gPXE.
Its very possible that booting gpxe.usb from a flash stick or gxpe.iso media it won't be a problem, the USB Ethernet device will be detected, and the Boot File path will be used to pull down a configuration file to further download the next stage.
Actually this is kind of okay.. because that means the gpxe.usb image can be generic, and its boot target is set by the dhcp server and then any processing logic for selecting the image would be up to the http server providing the target file gtest.gpxe (http processing could hand out a different file based on IP address for example).. which was assigned based on mac addr or even mac vendor code anything dhcp can key off of when assigning an IP. (Or) the next stage could be a menu selector that download other choices.
7/23/2014
PXE, Sys etherboot gPXE and iPXE
PXE has a long history
But essentially its a 16 Bit program that uses the environment setup by an x86 BIOS bootloader to then pull another bootloader across a network and then starts that.
PXE is a routine that implements a [step] on the way from boot a machine to executing an operating system.
BIOS gets a motherboard, systemboard, or pc computer running, from power on it tests then manually configures all the attached devices to make them ready for the programs that follow.
BIOS also has a long history, from the IBM PC to the Phoenix and AMI versions of the original up to the present day.
IBM published its BIOS code and the versions that came after used it as a means to produce a set of assumptions called the Application Program Interface (API) to then write code that could take over and continue the process of getting work done.
Microsoft wrote a "kernel" to take over this job and it had a driver API and a DOS programming API.
Linux had similar "kernels" and a choice of pre Linux kernel "bootloaders", Lilo, Grub, Syslinux
PXElinux is a variant of the last to pull the final Linux kernel piece over the network and start it up.
Etherboot was a project to place a netboot or PXE code in a network adapter ROM so that BIOS would chain to it and start it up, by-passing the need for a local mass storage device, or to rewrite the BIOS code such that it included these routines.
gPXE was an attempt to modularize and enhance Etherboot.
iPXE was a branch or fork from gPXE that took a different direction to do similar things
Meanwhile Syslinux continued to do what it did very well, it bootstraped existing BIOS boot devices from anything the BIOS could itself boot from, into later bootstrap or kernel code.
Syslinux support for iPXE was attempted to unify and benefit both, letting each specialize in what it did best.
Neither Syslinux or iPXE had code to support USB devices.. exactly, some BIOSes will support native Flash or Memory chips which are inserted into SD or USB slots for booting. But generally do not have generic support for all the possible types of USB devices that might be inserted into a slot connected to a USB controller that is supported by a BIOS.
A USB network adapter is a USB device with an Ethernet controller at the end of a USB cable. When it is inserted into a USB slot, the BIOS must recognize the event, then initalize or setup the device and support communications with it. Then any program that needs to use it for network communications, like a PXE routine, must further initialize the network controller across the USB bus for communications and then carry out a few simple operations to download and execute an additional bootstrap or kernel code.
In order to add USB network adapter support to the Syslinux or iPXE bootloader code, a driver needs to be created to seek out and start or work with a USB controller, then command it to find the USB network adapter on the USB bus and initialize it for communications and carry those communications out.
First we need a development platform.
Centos 5.9 i386 with EPEL for RHEL 5.4 enabled running in VMware Player will suffice.
Then we need a USB network adapter and a USB bus and controller to work with.
VMware Player is known for good USB 2.0 controller support.
So we can connect a USB network adapter to the VMware Player host and connect it to the virtual machine, then run the command "lsusb" to detect the USB device the Linux kernel detected upon insertion.

This obviously worked indicating I attached a ASIX AX87722A Fast Ethernet 10/100 Adapter
Technical documentation and driver source code for a Linux kernel is available here:
AX88772A Drivers Download
For Linux kernel 2.6.9 to 2.6.13 ( 9-11-2007 )
The driver source appears as a single .C file and .H header file that produces a single usbnet.ko module file which can be compiled and linked with linux kernel libraries and code to produce a driver to support the AX88772A chipset, taking advantage of the linux kernel support for the USB bus chipsets.
The [Readme] file in the source code tarball seems to indicate it supports both types of ASIX adapter
ASIX AX88178 USB2.0 Gigabit Ethernet Network AdapterBalaji Rao already appears to have tried to add USB network adapter support to gPXE here
ASIX AX88772 USB2.0 Fast Ethernet Network Adapter
Enabling gPXE to use USB Ethernet Adapters
iPXE shares a common ancestry with gPXE, so it would make sense to investigate the approach he took and see if it could be used to enable iPXE to use USB Ethernet Adapters.
As far as I could tell (and this is second hand information) Balaji started the project inbetween jobs and ceased working on the project after acquiring a new position.
He did create a Git repository which can be checked out:
# git clone git://git.etherboot.org/people/balajirrao/gpxe.git -b usb

There is a browse-able Git repository view here:
http://git.etherboot.org/people/balajirrao/gpxe.git/

The work appears to have stopped 8-21-2008 around 5:50 pm
From the log entries it appears he got support for OHCI and UHCI controllers working, and targeted specifically the USB network chipsets

Changing into the locally git clone repository and then into the src directory and typing the "make" command results in a stream of compilation messages including :

Which indicates [bin/usbcore.o][bin/urb.o][bin/uhci_hcd.o][bin/ohci_hcd.o] all cleanly compiled for gPXE. Those "appear" to be similarly named components for a USB bus support system under Linux recreated in a gPXE kernel environment.
Later [bin/asix.o] "appears" to be cleanly compiled

This entry suggests ASIX 88772 support might exist within the code
struct usb_driver asix_88772_usb_driver
This entry suggests he was using QEMU to start and test the code in a virtual machine and ran into some problems around 8-3-2008
[USB] Control transfers work properly as verified by qemu debugging messages. But its still qemu crashes for some reason.
This entry on 8-12-2008 suggests he got ohci code working
[USB] OHCI now works on bare metal.
This entry on 8-14-2008 suggests he got USB working
[USB] Kind of works..

from this we can [kind of] conclude he got it working.
It appears to me he based his design on the modular USB support developed for the Linux kernel and ported or re-implemented it in the gPXE kernel environment. Because of the mention of URBs I assume once he got the OHCI controller working, adding support for the UHCI support did not take much more effort (or he didn't have the hardware to test it).
Specifically it looks like he got an OHCI controller to work with possibly an ASIX AX88771 based USB network adapter after modifications to the OHCI and ASIX code.
Replicating his success, would be a good first step to broadening the support.
Another interesting tidbit:
Balaji seems to have documented using qemu to test gPXE.usb compilations here:
Using gPXE with QEMU
Build the gPXE from the instructions in the gPXE tarball. There will be a gpxe.usb file created in src/bin/ directory. That will be the USB image of the gPXE ROM which can be put into a bootable USB mass storage device. Now execute the following command
qemu -hda bin/gpxe.usb -net nic -net user -bootp http:/etherboot.org/gtest/gtest.gpxe
http://quark.entity.com/gtest/gtest.gpxe
represents where to download the kernel from using PXEQemu usb data snooping
While working on gPXE I had to snoop USB data for various reasons.
Here's how to do it.
QEMU
If your testing gPXE using QEMU, then your in luck. You can uncomment the lines starting with #define DEBUG_* in the QEMU source code and recompile. Now when you run QEMU, you get a tons of very valuable information from the console.
This will make QEMU run a bit slow. But who cares when they're debugging! The best thing about this approach is that the data being printed by QEMU is in a user readable format.
USBMON
This method is a bit involved. First you have to mount the debugfs in /sys/kernel/debug. Then change to the mounted directory into a directory called usbmon. There you'll see many files similar to 0t,0u,1t,1u,2t,2u etc. The files prefixed with a ‘u’ are supposed to provide output in a newer format. The number represents the kernel assigned USB bus number for a controller. The bus number your device is connected to can be obtained by running # lsusb.
Once you’ve found the bus you can (for example) ‘cat 3t’ to see tons of information of this form.
The format of the output is documented in a in text file located in the Linux Kernel Documentation/. You can also get it here.
This method is commonly used by device driver writers.
The device they're writing a driver for is connected from a Linux host via a pass-through-ed to a QEMU virtual machine. Then they run some OS like Windows in the QEMU virtual machine and when the windows driver interacts with the device, it can be snooped.
Examining the interactions, people reverse engineered Linux drivers from the behavior of the Windows drivers!
This is consistent with the git repo commit comments.
Another way is to mount the usbmon fs and then use Wireshark to treat the USB buses like network interfaces and "interpret" the USB traffic on the fly.
Sniffing USB Traffic - Different Approaches
usbmon captures
On my system, I do this:
modprobe usbmon mount -t usbfs /dev/bus/usb /proc/bus/usb
After that, run "tshark -D" to list all the interfaces. You should see theusbmonXinterfaces listed. You'll need to figure out which one is applicable to your device, but that shouldn't be too hard if you run "cat /proc/bus/usb/devices".
For example, if your device shows up as "Bus=04", then you need to capture using "tshark -i usbmon4". And of course, if you want to save the packets to a.pcapfile, then you also need to specify "-w outfile".
You might also take a look at: http://wiki.wireshark.org/CaptureSetup/USB
Useful tips:
# modprobe asix
# modinfo asix | grep v0B95
# lsusb -t
# qemu -cdrom gpxe.iso -net nic
> CTRL-B
>gPXE config
(Interesting progress in testing the code)

So.. in VMware Player, Centos 5, running qemu virtual machine booting from the gPXE.iso with the ASIX driver (apparently) the code [does] recognize the ASIX AX88772A based USB-2-NIC adapter I had attached to my desktop, pass-through VMware to the Centos virtual machine, pass-through to qemu virtual machine and assigned to net0
# lsusb -t
Bus# 1
`-Dev# 1 Vendor 0x0000 Product 0x0000
`-Dev# 2 Vendor 0x0b95 Product 0x772a
Red Hat 5 (Centos 5) appeared to have a problem loading gpxe.usb images so I used the gpxe.iso qemu cdrom option instead.
Also the qemu -device option wouldn't be available until a later version, so I used the -usbdevice option instead.
# qemu -cdrom gpxe.iso -net nic -net -user -usbdevice host:0b95:772a
really did not expect that to happen, it appears to initialize the USB controller and correctly identify the ASIX chipset and load that driver.
By re-routing the VMware connection to the host system, a Windows 7 desktop, I can confirm the MAC address for the ASIX USB-2-NIC adapter does indeed have that MAC Address

Next Day
centos already has usbmon built-into the kernel so # modprobe usbmon doesn't work, however simply mounting the debugfs does work, and you can cat 0t or 0u usb controller communications.
note to self: installing the vmware-tools and running the setup config makes handling gnome so much nicer, hello dynamic screen resolution
Wireshark did not get USB packet decode capability until version 1.2 the default yum repo for centos 5 only has wireshark 1.0, there don't appear to be repos that have it back ported or back compiled or back packaged.. but the source code is available. I saw a recommendation to us fedora 14 src packages for Wireshark 1.10 and that should compile.. maybe
# mkdir ws
# cd ws
# wget http://www.wireshark.org/download/src/all-versions/wireshark-1.2.0.tar.gz
# yum install gtk2-devel
# yum install libpcap-devel
# unpack the ws source
# ./configure
# make
# make install
Wireshark needs at least libpcap 1.0 to support usbmon, centos 5 only has libpcap 0.9
# mkdir lp
# cd lp
# wget http://www.tcpdump.org/release/libpcap-1.1.1.tar.gz
# tar -zxvf libpcap-1.1.1.tar.gz
# ./configure
# make
# make install
Recompile Wireshark to use the replacement libpcap libraries
#cd ws
# make clean
# ./configure
# make
# make install
Coencidently Matt Cutts has nice article on 'Compiling a USB Program' with lots of how to references
http://www.mattcutts.com/blog/compile-a-simple-usb-program-in-linux/
Useful qemu options
http://doc.opensuse.org/products/draft/SLES/SLES-kvm_sd_draft/cha.qemu.running.html
Refined qemu start command [doesn't create a virtual pci nic to distract things]
# qemu -cdrom gpxe.iso -net none -usbdevice host:0b95:772a
# mount -t debugfs non_debugs /sys/kernel/debug
# /usr/local/bin/wireshark
Step by Step
Finally capturing and analyzing USB packet traffic 'Live'
So now I can start tweaking the code to see why it's not pulling a dhcp address.

7/22/2014
iPXE, support for USB NIC booting
Syslinux is an awesome toolkit by highly talented H. Peter Anvin, next to Linus Tovald he's one of the brightest people I've ever known.
A while ago I messaged him about the idea of USB NIC support in iPXE, since that seemed to be the successor to Etherboot.
The idea was that since isolinux, syslinux and pxelinux were all bootloaders exploiting the native 16 bit BIOS to do various things.. as if it were a mini-operating system.. how about adding USB NIC support?
It's a little more complicated than I thought.. first you have to figure out how your going to get your initial boot loader running. For Syslinux or PXE Linux that involves the native BIOS bootstrap loader that initializes and loads code from a hard disk, or configures and downloads code over a "supported" Ethernet device plugged into something like an ISA or PCI bus.. PXE Linux is great, but it still needs a minimal hardware driver to support that "bus" that acts as a bridge to the network card or adapter.
Since BIOS normally initializes the ISA or PCI bus, that step is pretty simple, its already done by the time your code starts executing, then all you have to do is probe for the attached network hardware and initialize that.. and perform a dhcp protocol routine and a trivial file transfer to download the network boot program (according to the PXE protocol) and turn control over to that.. mission accomplished.
Peter worked with several groups to bring Syslinux and PXE Linux up to where it could work with the myriad ethernet device drivers that were becoming a part of the etherboot, ipxe and gpxe projects.. code reuse is very valuable and orchestrating an interface between multiple code bases is a true skill.
So that bridge crossed, what about USB NICs and PXE support?
Well in theory you would need to bootstrap your code via one of the mechanisms of the BIOS, a hard disk, a different PCI network adapter, ect.. and then load a driver you wrote to "initialize" the USB hardware so that you could then "probe" the USB bus for a network card or adapter and then "initialize" that.. once the hardware is setup and "Ready" then the iPXE or some other PXE code implementation being reused can take over and finish the PXE protocol and download another bootloader program.. like for instance an installer kernel.. or a whole network operating system kernel.
The problem here though.. is something has to initialize the USB hardware, if the USB controller is built into the system the BIOS probably already does that, but it may only support things like a keyboard, a mouse, ect.. and almost surely won't have support for the specific USB NIC chipset in your USB dongle.. there are just too many of them.. the odds are against it.
And to make it more complicated, there have been USB 1.0, 1.1, 2.0 and 3.0
How you set them up and use them varies quite a bit. They are generally different hardware chipsets.
So let's narrow the scope to those most likely to be encountered, say USB 2.0 and USB 3.0 then go further and say only one specific chipset of each.. your USB NIC driver then has to interface with each of those to find and initialize the USB NIC chipset.. not impossible, but this is mostly 16 bit assembly code.. even if written using mostly C or C++ to pull the assembly "strings".
A person did start down this path
Summary This project will enable gPXE to use USB Ethernet Adapters. This includes, Adding USB support to gPXE. Writing a network device driver for an USB Ethernet Adapter.
(not me), for what its worth, here are my notes:
centos 5.9 i386 with EPEL for RHEL 5.4 enabled and yum updated
then
yum install git
check out the git branch - that appears - to be - the one merged up to from ohci <- which is the oldest branch
# git clone git://git.etherboot.org/people/balajirrao/gpxe.git -b usb
cd gpxe/src
make
appears to compile cleanly, almost
Next Steps
Two avenues, study the "Balaji Rao" code base, or consider borrowing an existing USB driver code base from another kernel.. use whatever hardware I have on hand. With an eye to broadening the base to support other USB controller chipsets, and USB NIC chipsets later.
And also another option is let BIOS initialize the USB chipset and simply assume its ready and "use it" rather than setting it up again. Tricky but possible.
Assuming Phoneix or AMI have some standards for their BIOS Interfaces for USB chipset support.. then it becomes a matter of "finding" the USB NIC and identify its chipset type and initializing it, then handing it off to the PXE driver routine.. mission accomplished. I rather like this idea, but I do not know enough about Phoneix and AMI 16 bit programming or where to source public information on this topic. I would think the USB Chipset vendors themselves would publish some reference 16 bit BIOS drivers and those might be integrated or adopted by Phoenix or AMI.. since its in the interests to sell most chips by volume.. the information might be fairly common and available.
SMSC provided some input to the Linux kernel in 2008 providing what looks like a driver for their USB NIC chipset here:
SMSC LAN9500 USB2.0 10/100 ethernet adapter driver
Another useful link: (taking apart an ASIX usb to nic adapter)
Anatomy of a cheap USB to Ethernet adapter
7/21/2014
Degeneration, Aging and Diabetes
I read an article the other day about a women who lived a long life, and then died having only two stem lines left for her immune system. That's the loss off a lot of diversity.
Blood of world's oldest woman hints at limits of life
If true then white blood cells, which have the unique ability to squeeze into tissues and organs and between cells without damaging them, could represent the universal "Stem" cell repair mechanism that pervade our bodies and performs not only immune protection, but regeneration in every tissue of the body.
Aging might just represent the loss of the ability to regenerate over time.
All cells obey the Hayflick Limit, which until relatively recently wasn't understood, to be the result of repeated cell division that chipped away a little at a time from the end of the DNA strands in each cell, the ends are called Telomeres.
Somewhat akin to the interstitial "gap" required between information sequences in a "frame" of data. Once it erodes away, the information between frames becomes mixed and corrupted.. quite literally "exposing" the Gene sequences to unprotected and unlimited corruption.. so the cell stops dividing and essentially dies. It is a noble death however, since unrestricted growth without control is the hallmark of cancer. Cancer is a curious phenomena though, since it seems only specific "accidents" lead to the familiar patterns of cancer that we know of today.. there don't appear to be an infinite diversity of cancers.. but rather limited classes.. suggesting they may depend on opportunistic "junctions" where Telomere erosion fails to initiate a failure to continue to replicate. Ultimately cancer treatments may develop which target these "junctions" recognizing they have been "jumped" or violated and used as demolition "markers" for White cell lines programmed to target cells with these conditions.
I rather like to think the old Star Trek: Enterprise - "Dr. Flox" (Memory Alpha)
He gained the confidence of the Novans when he cured Nadet, an elder Novan, from lung cancer.
replicating the "cyto-lytic" enzymes referred to custom making a therapy from a patients White cell lines to target such "junctions" and thereby deliver the treatment to those specific cells no matter how deep in the body, and only to those cells.. special delivery "the gift of death" to those that should have died the noble death so that the person might live, but through chance were unable to. (note: scientists are getting very close to this type of Science Fiction, targeting the removal of the HIV genome from human cells, and vaccinating white cells from infection)
When you think of it White cells are amazing.. the ultimate scalpel and hypodermic.. able to go anywhere.. without harm.. and able to do anything necessary. Radiation beams and Chemotherapy seem incredibly harsh and overbearing by comparison. If only we could guide them in the right direction.
And if this be true of cancer.. someday.. in ourselves.. or generations to come.. we might be able to selectively remove these dangerous junctions.. or shore them up with booby-traps and trip-wires in the DNA code itself as In-trons which protect.. or call for assistance from White cells to eradicate and prevent cancer.
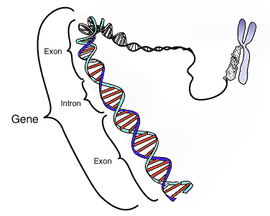
One theory of aging is its the "end" to replication, or "regeneration" which leads to degeneration of organ tissue and we literally "fall apart" until a catastrophic condition occurs.. a critical artery bursts, in the wrong place at the wrong time.. plaque builds up because normal repairs fail, and a secondary backup system that relies on "plaque" as if it were household "spackling paste" seals an old wound, or a deficit, the surrounding cells can no longer repair.
When you think of it, aging might be a merciful slow death.. as opposed to a quick, sudden and tragic death.. it may be an experiment in biology that has extended our lives.. if only for a little while.
White blood cells with their unique ability to squeeze almost anywhere in their relentless pursuit of germs and bacteria, even rogue cells that have become cancerous, may as "Stem" cells differentiate into other types of cells like organ cells and act is a secondary if not primary method of making repairs throughout the body. Certainly once organ cells reach the Hayflick Limit.. something, anything.. must be done to regenerate the tissue or we would die immediately.. rather than degenerate at a slower pace. It could be the many White cell Stem cell lines are providing this function.
Reducing their number and diversity is surely a measure of aging, as they undergo many divisions in their constant assault from everyday life. The more often we are sick, probably the fewer White cell Stem cells lines are left.. shortening our lives. Inflammation has been blamed for this, but the site of inflammation is also the site of the most White cell activity. A marker they are being "used up".
Looking at it this way, I can see all of the organs and cells of the body are constantly being eroded by the activity of life.. like sand paper.. the sands of time wear us down.
Diabetes for example must be a lot like this, assuming the Type 2 which appears to be a result of life style more than a mystery. The accelerated introduction of high blood sugar, ( whether by diet, disease or anything that provokes a higher than normal blood sugar level.. must "wear" the Islets of Langerhans down. I would imagine exposure to some pathogens or diseases can wear them down faster than others and contribute to a cumulative reduction in pancreatic blood sugar control.
This might also explain life extension through deliberate calorie deficit. I always thought it was the principal of.. the less chemical reactions per cell.. the less "that can go wrong" even if something like cancer were inevitable.. it would on average take longer to actually occur. But this new line of thought brings to light, a calorie deficit may simply not "grind" our cells down into the dust as fast.. so living fast leads to a short life.. living slow.. leads to a long life.. as a mantra, kind of makes sense, in multiple ways.
We've never really had much of an opportunity to "over consume" and in "selective ways" the foods that give us the most pleasure and manipulate our brain chemicals much like addictive drugs in all of history. But for now, we can.. and a grand experiment is underway.. perhaps even a Darwinian process of weeding out entire familial lines that cling to convenience.. or some type of belief that leads them to control, not just diet and lifestyle.. but the rate of exposure to infectious disease.. and perhaps even controlling sleep patterns and "chosen" patterns of exercise. The "have Health" and "Healthy nots". Curious how we use similar reasoning that the choice is not under our control, or too hard and practically uncontrollable like a force of nature. Seems similar arguments applied to Tobacco, Alcohol and recreational drugs at one time of history or another across many cultures.
We still are not at that point when monitoring our blood glucose levels is delegated and taken care for us minute by minute.. such that we don't have to think about it.. but with things like the bloodless Grove Instruments meter.. and the Google contact lenses that measure those things perhaps that day will be coming soon. I truly wonder then.. when we do have the choice and its relatively easy.. will this extend human life.
HPSIM, Hyper-V guest WBEM enabling
HP SIM does not use WS-MAN for anything other than ILO or Onboard admin management processor.
HP SIM does use WBEM and SNMP as a way of remotely accessing WMI for Windows Server 2003, 2008, 2008r2, 2012 if the WMI Mapper is installed on Windows server.
[note: remember! for WS2012 if you install the SNMP Feature/Role, to access it through the "Server Manager" as opposed to using the legacy MMC services.msc plugin, otherwise a reboot will be necessary to see the SNMP configuration tabs, "Server Manager -> Tool -> Services" will display them immediately without a reboot]

There are several flavors and versions of the WMI Mapper, the one that comes with HP SIM, the one that is separately downloadable as a Windows MSI package from HP. And the ones that seem to be released as updated versions for all of the above.
I have found the latest doesn't seem to work as well as the older versions, and the change_logs seem to bare this out as a dependency problem that isn't well explained.
Therefore since we use 2008r2 and 2012, I chose to use the [ WMIMapper2_6_0.msi ] package on both the 2008r2 and 2012 versions of Windows servers.
In HP SIM
Options -> Protocol Settings -> WMI Mapper Proxy...
is used to configure a host that has a WBEM (WMI Mapper Proxy) service. In general I believe this is intended not to only map a single Host behind a firewall, but to perform the WMI mapping function for a whole subnet.. but it works just as well for an individual Host. So add the Public or Private IP address through which the "Host to be managed" will be accessed over port 5989.
So first the WMIMapper2_6_0.msi packager is copied to the target Hyper-V guest system that is to be managed and installed.
Then the Hyper-V guest system Firewall is configured to allow communications on the 5989 default port for WBEM traffic.
Then the Hyper-V guest system [Administrative Tools -> Component Services ->][Console Root -> Component Services -> Computers -> My Computer][Rt Click Properties][COM Security][Access Permissions][Edit Limits...][Security Limits -> Add -> domain\user][Permissions [x] Local Access [x] Remote Access] is granted.
Then the Hyper-V guest system [Administrative Tools -> Component Services ->][Console Root -> Component Services -> Computers -> My Computer][DCOM Config][Windows Management and Instrumentation][Rt Click Properties][Security][Launch and Activation Permissions][Customize][Edit...][Security -> Add -> domain\user][Permissions for Authenticated Users] [Local Launch [x] Allow][Remote Launch [x] Allow][Local Activation [x] Allow][Remote Activation [x] Allow] is granted.
Then the Hyper-V guest system [Administrative Tools ->Computer Management][Service and Applications][Services][WMI Control][Rt Click Properties][Security][Security (button)][Permissions for Authenticated Users][Advanced (button)][Add -> domain\user][Applies to: This namespace and subnamespaces][Permissions][x] Execute Methods [x]Full write [x]Partial Write [x]Provider Write [x]Enable Account [x]Remote Enable [x]Read Security [x]Edit Security is granted.
Finally an HP SIM -> Options -> Discovery task is configured, with [Credentials]-> [Advanced Protocols] ->[WBEM] and the domain\user and password are provided which was "granted" access to the DCOM service and the WMI datastore.
[NOTE: Do not FORGET to create a Special Rule in the Windows Guest Firewall to permit access to port 5589, or the WBEM service will not be accessible !!! ]Upon running the Task, WBEM service will be discovered, and the credentials will be indicated as "valid" and working and the virtual machine guest hosts will be added to the default [Servers] container as a managable node. Pretty seamlessly.. the frustating part is that this is WBEM over a proxy agent called something like "WMI Mapper proxy..." which is entirely unintuitive from a Microsoft (who would have intuited WMI is a WBEM protocol service source?) and HP (who would have intuited that setting up a WMI Mapper proxy... source would grant access to a WBEM protocol service source?) and RPC/DCOM protocols default on the operating system to local administrative accounts accessing only locally (not remotely) would be enabled.. meaning you have to "grant" DCOM and WMI access rights? (again.. not intuitive)

The reason all of this is necessary and why it works, I believe is because port 5989 is the default port for WBEM traffic as part of a specification, Microsoft already had their version of WBEM called WMI built upon the RPC/DCOM methods supported by the WMI protocol, which unfortunately were not WAN friendly like WBEM.. that is available over a single fixed TCP port. Microsoft RPC/DCOM is based on a moving target range of ports assigned and indexed by an RPC locator service which doesn't exist as part of the WBEM protocol.. and in fact fixing it tends to break certain features.
So a true WBEM protocol Mapper called rather unintuitively a "WMI Mapper" translates true WBEM protocol port calls into local WMI Mapper calls to the WMI service on the Host and back again. In theory the WMI Mapper can also act as a gateway to other machines on the same subnet.. but this seem to run aground when dealing with local LAN complexities of remote invocation of RPC calls and default security.. which is what the last three steps are all about.. enabling a "Domain" wide user account permission to use the Remote Procedure calls through DCOM to access the WMI data store.. and finally granting access to that data store.
WS-MAN was to be a replacement for all of this and more closely align Microsoft WMI with WBEM, however HP SIM is a project that developes over time and ceases development periodically then resumes (except it is now scheduled to be retired in a couple of years).. and only used WS-MAN (the official RFC version) for managing some of their equipment, but not all operating systems.. so while WS-MAN is supported for HP equipment it is not for Microsoft operating systems.
Thus the best, only way to remotely manage a Microsoft operating system without Insight SNMP agents, or WBEM agents written by HP, for example on a Hyper-V virtual machine with no native HP SIM agents or "supported" WBEM capability.. is to install the HP SIM WMI Mapper package and add that as a WBEM proxy to get to the native WMI source on a virtual machine guest Host.
When its all done, HP SIM detects all that it needs to manage a Hyper-V virtual machine guest running Windows 2008r2 or Windows 2012 and properly recognizes it is of type "virtual machine" and is indeed a "virtual machine guest".
Another plus is that while you can "try" to install Insight SNMP agents on a virtual machine it will halt and not complete complaining "install not supported on virtual machine guests".
The WMI Mapper package however does install on a virtual machine, probably because installing the WMI Mapper on a SIM Host is supported on a virtual platform.

More Information includes additional details sourced from the WMI CIMOM datastore, status and configuration tabs appear to perform live inquiries directed at the virtual machine on command.

7/07/2014
KVM, enabling virtio after P2V
We run some virtual machines on Red Hat Enterprise Linux (RHEL) version 5 using KVM.
Kernel Virtual Machine (KVM) on Red Hat is managed by libvirt or other management tools to configure, start and stop and maintain the virtual machine. Its an open specification so there are many command line and GUI management tools available.
The tool we use is Convirture, which is a bit like Ovirt or Openstack, in that a MySQL database backends a Web Console for overseeing the creation and management of common resources like shared storage and shared network bridged adapters in order to support high availability migrations of virtual machines between a cluster of host nodes.

So when a virtual machine is created or provisioned, it can be installed using the native installer, or "adopted" by migrating it from a Physical deployment on a dedicated server into a virtual machine. There are tools to assist doing this like disk2vhd for windows or virt-p2v for linux.
useful links:
virt-p2v and virt-v2v
summit talk on libguestfs virt-v2v
Inception -> Super nested KVM -> "Or how I learned to Not Fear the Matrix and Love the KVM"
After the original volumes are converted into raw or other acceptable virtual machine volumes, a virtual machine configuration or set of definition files can be created in order to wrap and support booting the volumes as a new virtual machine.
Initially the virtual machine will only have the drivers included at the time of the original install on the Physical server hardware. Which means the virtual machine "emulation wrapper" must coencidentally emulate hardware, for which, the original Physical volumes had drivers. These are often enough to get the virtual machine to boot, but are not optimum for performance reasons for the operating system in the new virtual environment.
A common relatively open alternative are virtio drivers.
M. Tim Jones,
"virtiowas developed by Rusty Russell in support of his own virtualization solution calledlguest. Linux is a hypervisor playground. Examples include the Kernel-based Virtual Machine (KVM),lguest, and User-mode Linux. Rather than have a variety of device emulation mechanisms (for network, block, and other drivers),virtioprovides a common front end for these device emulations to standardize the interface and increase the reuse of code across platforms.
In full virtualization, the guest is unaware that it is being virtualized and requires no coding changes to work. Conversely, in paravirtualization, the guest operating system is aware that it is running on a hypervisor and includes code changes to make guest-to-hypervisor communications more efficient.
In the paravirtualization case the guest operating system is aware that it's running on a hypervisor, the coding changes are implemented by includingvirtiodrivers that act as the interface between the guest and the hypervisor. The hypervisor implements back-end drivers to support the specialized guest device emulation. These "in-guest" and "in-hypervisor" drivers are wherevirtiocomes in, providing a standardized interface for the development of optimized emulated device access to promote code reuse and increase efficiency. "
Virtio drivers partner with a version of the Linux kernel that has included support for virtio to bypass most of the emulation layers and provide near bare metal speed to the virtio drivers operating in the virtualized operating system enviroment. Often a speed of at least x10 performance can be obtained.
Virtio drivers for "block devices" or SCSI hard disk drives are available.
Virtio drivers for "net devices" or network adapters are available.
Taking the example of Windows 2008 r2, once it is booted and working under emulation.
We shut it down and created a new disk volume, solely for the purpose of [triggering] a Plug-n-play install of the virtio driver for the new disk volume.
First to create the disk volume with our version of Convirt, we had to drop to the command prompt and execute the following command:
# qemu-img create -f raw elm-2.img 1G
This created a new 1 GB raw disk volume that we could attach to the virtual machine while it was shutdown.
Next we modified the virtual machine [Virtual Machine Config Settings for ELM] by selecting [ Edit Settings] and selected the [Miscellaneous] option, so that we could add a virtual machine startup parameter that does not normally exist in most default virtual machine configuration templates.

The parameter to create is "attribute"
driveFollowed by "value"
['file=/vm_vol/vm_disks/elm-2.img,if=virtio,cache=writeback']Complete with the apostrophes and square brackets.
The content means nothing to the Convirture management system, but is understood by the qemu-kvm invocation that eventually takes place on the target host server to bring the virtual machine into existence.
file = designates the [raw] disk file volume
if = designates the interface or 'bus' the volume will be attached to, the host linux kernel already understands this type of bus and makes it available to the virtual machine
cache = designates the behavior the host takes when the virtual machine attempts to perform a disk io operation, for which there are tradeoffs, if uncertain, do not include it
For the 'guest' operating system, in this case Windows 2008 r2 (which is x64 bit) a virtio driver will need to be obtained and made available to it once it boots in order to add support for the if=virtio bus type.
The most conventional if quaint way of doing this is to provide an .iso file with the drivers included in the image.
You have to be aware and careful to match the virtio client or 'guest' drivers to the virtio support in the linux kernel, mismatches 'may' work, however client drivers that are too advanced of the linux kernel they are demanding service from, may over reach the current feature set of that linux kernel and result in an inaccurate report of driver compatibility, or down right failure to service the client driver.
In otherwords, your windows guest may "blue screen".
So, we are running RHEL v5.10 on this virtual machine host.
There are several sources of virtio client/guest drivers, Fedora, the linux-kvm.org project or Red Hat if you have a current subscription. Even Microsoft offers a links to them Windows Server Catalog
In our case since we are current with Red Hat Subscription, so we navigated to:
https://access.redhat.com/downloads/content/69/ver=/rhel---5/5.10/x86_64/packages
And type in "virtio" into the Filter box to arrive at a download link to the rpm:
virtio-win-1.0.3-0.52454.el5.noarch.rpm
Inside this rpm are many files including
virtio-win.isoWhich can be accessed whether by extracing with 7zip or cpio or rpm2cpio or simply installing the rpm on a host and then tracking down the iso file with an rpm -ql command.
Since this file is intended for guests running on the version of kernel that comes with RHEL v5.10 we can be assured of maximum compatability in our situation.
To get the contents into the guest image, we booted the image using normal procedures and let the plug-n-play process attempt to perform normally after detecting a new interface bus.
However..
It did not install the driver.
So we manually traversed the mounted cdrom iso image inside the virtual machine, located the correct driver for an x64 bit operating system and executed the installation program.

This installed the driver, and indeed opening the Device Manager and checking for a new SCSI device indicates Bus support for the Red Hat Virtio SCSI bus.
However..
It did not bring the attached raw volume online.
To do that the Windows 2008 Manager Storage MMC applet needed to be used to "browse" the attached storage and recognize the volume was detected, but "offline" merely selecting the [tab] to the Left of the drive volume and then "Online" brought it online.
Mission accomplished the virtual machine was shutdown again.
So that the temporary volume could be removed from the virtual machine configuration, and then the two existing [disks] could be converted to [drives] using the if=virtio type.

The completed [Miscellaneous] attribute value pair are the following:
attribute
drive
value
Take note: The first volume also has [ boot=on ], and the second drive comes up "offline" as well.
['file=/vm_vol/vm_disks/elm-0.img,if=virtio,boot=on,cache=writeback', 'file=/vm_vol/vm_disks/elm-1.img,if=virtio,cache=writeback']
Take note: While MPIO is an option for iSCSI, its not something to enable "accidentally" when moving from the "disk" type to the "drive" type in the virtual machine configuration, be sure to [ remove ] the storage entries for the disk file volumes under the Convirture [ Storage ] section, or where appropriate in your virtual machine manager configuration.

After the first boot in this configuration, the second drive will need to be brought online manually.
After this first boot "bring second drive online manually" procedure, on subsequent boots the second drive will be brought online automatically.
Based on my previous experience with VirtualBox and other vm technologies, the cdrom emulation was left on the ATA/IDE bus.

Changing from the default emulation to using virtio for network adapters is a lot easier.
First you can run the .msi Microsoft installer from the cdrom image to pre-install the drivers, in which case when the emulation type of the hardware changes it will simply install from the preinstalled pool of available drivers.
Next you shutdown the machine and then navigate to the [Network] section of the settings and choose to modify (at least in Convirture) the [model] of the bridged network adapter. The drop down provides many emulation types to choose from, including the [virtio] type.

Restart the virtual machine and the virtio driver will be installed to support the new hardware, the old network adapter and its TCP/IP setting will be gone.
However if you didn't write the settings down, they will still be available for reference in the Controlset in the Windows Registery.
When configuring the new adapter with the old TCP/IP settings, you may find a warning a message that those settings are currently assigned to a "missing" network adapter, and an offer to remove them from that adapter so that they can be assigned to this new adapter. Generally it is okay to do this.
Benefits from virtio drivers will include lower CPU utilization, faster more responsive behavior from the operating system and generally lower memory use.
Subscribe to:
Posts (Atom)